
For enterprises that have stretched chatbots to their limit and still lack reliable, governed automation, the unveiling of a full-stack platform for autonomous agents landed less like a demo and more like a blueprint for production systems built to survive real traffic, real policies, and real audits. The keynote revolved around a vivid, multi-agent marathon-planning simulation in Las Vegas, but the substance ran deeper: a cohesive lifecycle that connected design and prototyping to deployment, evaluation, observability, and security, all framed by controls familiar to software leaders who manage microservices at scale. The pitch was not that models suddenly grew omniscient; it was that agents could be engineered with the same rigor as any enterprise component, from identity and policy to tracing and runbooks. This framing answered a growing concern in boardrooms and platform teams alike: how to turn model capability into dependable, auditable outcomes without fragmenting architectures or locking into a brittle stack that is hard to operate and harder to secure.
Core Thesis and Vision
Google positioned the platform as an end-to-end foundation for building autonomous agents that can handle messy, real-world tasks under governance. The throughline was Model Garden choice on top of Gemini-first defaults, evaluation that is segregated and testable, and runtime operations that feel familiar to SREs. Rather than celebrate novel loops or emergent tricks, the narrative emphasized discipline: agents that carry unique identities, run behind gateways that enforce policy, and register themselves for discovery so that orchestration flows through known, auditable channels. This was not an academic posture. It aligned with the hard requirements of regulated industries where identity, context control, and repeatable evaluation determine whether a proof-of-concept ever sees production. The result presented agents as software primitives, not experiments.
Building on this foundation, the keynote argued that multi-agent systems are maturing into networks of specialists. Planner, evaluator, and simulator roles took the spotlight, but the point was the separation of concerns, not theatrics. Each agent could select a fit-for-purpose model—Gemini Pro or Flash, or a third-party option via Model Garden—while complying with policies enforced at the edge. The platform’s lifecycle favored iterative hardening: start in a low-code designer, graduate to the Agent Development Kit (ADK), shift to a serverless Agent Runtime, and wire in observability and A/B evaluation as first-class citizens. This approach minimized fragile prompt spaghetti by encoding evaluation and guardrails as independent, reviewable components. In short, the platform sought to replace intuition-driven loops with principled engineering.
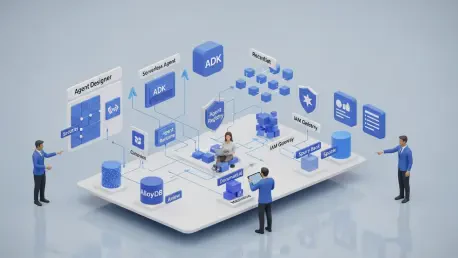
Platform Components and Developer Workflow
At the top of the stack, Agent Designer allowed teams to sketch behaviors and flows with low and no-code tooling, then export Python scaffolding from the ADK when deeper control was needed. That scaffolding arrived pre-filled with instructions and initial logic, reducing time-to-first-skill and encouraging better structure from the outset. From there, the Agent Runtime took over deployment concerns with a serverless model: scale up under load, scale down when quiet, and remove the operational drag of managing infrastructure for experimental and production agents alike. Model Garden’s role was pragmatic—choose Gemini variants for cost and latency targets, or swap in a model like Claude for a particular evaluator agent—without contorting the rest of the application. Such modularity kept the system honest; it allowed model debates to remain technical choices, not architectural rewrites.
Crucially, the Agent Registry acted as connective tissue. Deployed agents auto-registered for discovery, and inter-agent traffic flowed through the A2A protocol, which Google contributed to the Linux Foundation for community stewardship. Rather than informal JSON handshakes, A2A formalized how agents call, respond, and collaborate. The effects showed up immediately in the marathon demo: the planner did not need to know the evaluator’s model details; it needed only a registry entry and a contract. For interface generation, A2UI introduced a way for agents to render dynamic UI components instead of returning text alone, turning agent output into interactive panels with inputs, data tables, or visual overlays that responded to context. Combined with the runtime’s autoscaling and integrated logs, these components formed a coherent delivery pipeline from prototype to production, with fewer brittle edges and fewer opaque hops.
Governance, Security, and Operational Controls
The governance layer treated agents like service accounts with personality: every instance received a unique, immutable identity that followed it through runtime. That identity sat behind Agent Gateway, which enforced IAM-backed policies and access controls per agent, not per cluster or network zone. Fine-grained rules—no writes to a finance tool for a planning agent, or blocked open internet egress for a simulator—reduced the blast radius of both mistakes and malicious misuse. Because the controls lived at the gateway, revocation or policy changes took effect without code churn, matching how modern zero-trust stacks manage microservices. In an ecosystem where agent behavior can shift with a prompt change, that separation of duties mattered.
Security partners added external validation and remediation paths. Integration with Wiz introduced Red Agent and Green Agent flows: the former mapped potential attack paths, such as an authentication bypass leading to sensitive datasets; the latter proposed prioritized remediations, including IAM privilege downgrades or patching a misconfigured dependency. These findings moved through the same agent ecosystem, turning security into a continuous loop rather than a quarterly event. Post-remediation validation confirmed issues were resolved, closing the loop with evidence. For many enterprises, this converged with existing governance programs: agents became subject to the same identity, least-privilege, and audit regimes already in place, while still benefiting from the platform’s native observability. The message was plain—security was embedded, not layered on after rollout.
Memory, Data Grounding, and Multi-Agent Demo
State and context were treated as first-class. Session continuity flowed into a managed service called Memory Bank, giving agents durable memory without bespoke databases or ad hoc serialization. Retrieval-augmented generation integrated with the rest of Google Cloud: Document AI chunked unstructured content, Lightning Engine for Apache Spark preprocessed and transformed data at scale, and AlloyDB with auto-embeddings powered semantic search that actually respected enterprise schemas. In practice, this meant agents could cite company rules, interpret policy PDFs, and fetch procedural steps from certified sources rather than guess. The platform’s stance was explicit: grounded intelligence beats generic capability, especially when compliance and audit trails are on the line.
The Las Vegas marathon simulation served as a stress test for those ideas. A planner agent drew on a Google Maps MCP server to pull landmarks and geospatial data, assembling candidate routes through city streets and around constraints. A dedicated evaluator used a different model and a constrained context window to check the official marathon distance—26 miles 385 yards—while weighing qualitative criteria such as community impact or alignment with event goals. A simulator generated dynamic actors, from runners to vehicles, to pressure-test the plan under non-deterministic conditions. Developers packaged domain expertise as modular “skills” with YAML metadata and Markdown bodies, which agents loaded on demand. Dynamic interfaces, powered by A2UI, rendered hydration stations, medical tents, and traffic flows as interactive components. The point was not spectacle; it was an operational rehearsal that forced the system to manage state, reason over maps, and remain inside policy guardrails even as conditions shifted.
Openness, Interoperability, and Enterprise Next Steps
The demo also highlighted the gritty realities of operations. Under load, simulator crashes traced back to Gemini API request errors exceeding a one million context token limit. Tracing and logs built into the platform made those failures legible: ADK’s Event Compaction was not running frequently enough, which allowed token usage to balloon. Adjusting token thresholds and redeploying resolved the issue, a reminder that token budgeting belongs on the same dashboard as CPU and memory. Performance tuning followed the familiar SRE playbook. A “runners” component moved from Cloud Run to Google Kubernetes Engine for tighter control and lower latency, while a customized Gemma 4 model was colocated in the same cluster to reduce network overhead. Gemini Cloud Assist surfaced a model-loading bottleneck and recommended Lustre over GCS FUSE for higher-throughput storage, which improved warm-up times at scale. These adjustments cast AI systems as distributed systems, not magical endpoints, and demanded the same rigor teams bring to any latency-sensitive fleet.
Interoperability framed the strategic bet. The platform was Gemini-first but model-agnostic via Model Garden, A2A landed in the Linux Foundation, and A2UI arrived as an open proposal for dynamic interfaces. That triad tried to defuse the lock-in debate with implementation details rather than slogans. Perhaps the clearest signal came at the end: Google open-sourced the keynote demo and tooling so developers could reproduce the project. The release did more than share code; it shared patterns—segregated evaluators, memory hooks abstracted behind a managed service, token compaction schedules, and storage choices that shift with throughput needs. For enterprises staring down a roadmap of agents across internal apps and customer channels, those patterns offered a starting kit that blended AI engineering with the operational guardrails that leadership already trusts.
The Path Forward: Practical Moves That Delivered
For organizations ready to act, the most effective early moves started with the lifecycle, not the model. Teams defined agent roles—planner, evaluator, simulator—and mapped each to a model class in Model Garden based on latency, cost, and safety requirements. Prototyping began in Agent Designer to sketch flows and constraints, then shifted to the ADK for structural clarity and source control. From there, deploying to the serverless Agent Runtime created a safe boundary for scale testing without infrastructure toil. Instead of bundling evaluation into prompts, teams stood up a distinct evaluator agent with its own constrained context and metrics, making acceptance criteria observable and reviewable. This separation paid off during audits, where policies and thresholds could be inspected without reverse-engineering a chain of prompts.
The data path followed a similar cadence. Internal policies, runbooks, and reference documents were processed through Document AI, transformed with Lightning Engine for Apache Spark, and indexed into AlloyDB with auto-embeddings. Agents then pulled from Memory Bank for session continuity and used the RAG pipeline for factual grounding. Token discipline was enforced early: ADK Event Compaction ran on a schedule tied to workload patterns, while dashboards tracked context growth alongside API latency and error rates. When workloads spiked, critical components moved to GKE, and co-located models such as a tuned Gemma 4 instance were staged for hot paths. Storage choices were deliberate—Lustre over GCS FUSE where throughput mattered—based on Cloud Assist diagnostics. On the security side, immutable Agent Identities and Agent Gateway policies enforced least-privilege defaults, while Wiz’s Red and Green Agents supplied external validation and remediation. By the time user-facing pilots rolled out, the system had already been hardened under simulation, evaluated by a dedicated agent, and constrained by policies that auditors could read.







